

Hoy voy a hablarte de una técnica avanzada.
Y cada vez más utilizada en el mundo de los datos.
Es la segmentación o clustering.
¡Si!
Es algo similar a agrupar una tomates en: madurados, algo maduros… y verdes según el color y la “dureza” que observamos.
Dicho de otro modo. Una técnica capaz de:
Agrupar potenciales clientes en características parecidas según sus visitas y comportamiento en una web.
Crear grupos de pacientes parecidos según las características de su análisis de sangre.
Grupos de personalidad parecida según las contestaciones de una encuesta
Entre otros ejemplos…
Déjame contarte lo de los tomates con un poco más de detalle jejeje 😉
La caja de tomates o qué significa clustering
Mi familia es familia de campesinos.
Recuerdo que cuándo iba con mi abuelo a ayudarle en su huerto y cogíamos tomates había de todo.
Unos más verdes, otros más maduros, otros ni verdes ni maduros etc…
Me decía mi abuelo: “voy a apartar unos cuántos de verdes que a tu abuela le encantan, y estará contenta”
¿Qué hacía?
Observaba los más verdes o casi verdes e inmediatamente después los tocaba.
Si el tomate era duro lo apartaba.
Si era un poco blando lo dejaba en la caja.

En el fondo mi abuelo estaba poniendo en marcha un algoritmo de clustering o segmentación.
¿Por qué?
Primero por que observaba los tomates a partir de dos características:
- el color
- y la textura
Estas eran las dos características de su segmentación de tomates.
Una vez su cerebro recogía “estos datos”… segmentaba.
Ponía cada tomate (observación) en el grupo de tomates verdes para mi abuela y el resto como tomates más maduros.
Fíjate que aquí estaba segmentando en dos grupos.
En dos clusters.
Y esto es precisamente lo que podemos hacer con los datos.
Primero obtenemos características que podamos medir y cuantificar (color y textura en el caso de los tomates)
Y después agrupamos las observaciones en clusters o grupos con estas características similares.
La jugada es sencilla.
En el ejemplo de los tomates es sencillo pensar qué grupos vamos a obtener.
Pero en un problema más complejo (es decir, con más características a tener en cuenta) la cosa se complica.
Y las técnicas de clustering juegan un gran papel.
Antes de ponerte un ejemplo, comentarte que la técnicas de clustering es una técnica no supervisada.
Ya que a priori, no sabemos qué grupos existen en nuestros datos.
Un ejemplo de aplicación de segmentación de datos o clustering
Después de la magnífica segmentación de tomates de mi abuelo J
Vamos a por otro ejemplo, ahora sí, con datos:
Imagínate que eres profesional del sector vinícola.
Y dispones de una base de datos de diferentes vinos dónde has podido medir varias características:
- La acidez
- Nivel de alcohol
- Nivel de Magnesio
- …
Fíjate que son características de la composición del vino.
Con estas características podemos crear grupos de vinos de composición similar.
Es decir, grupos estadísticamente similares.
Esto es segmentación.
Y me preguntarás:
¿Cómo se puede calcular esta segmentación?
Y la otra pregunta.
¿Cuántos grupos (clusters) existen y son estadísticamente relevantes? O dicho de otra forma, ¿cuál es el número óptimo de clusters?
Vamos a contestar estas preguntas con un ejemplo.
DESCARGA EL EJEMPLO EN R
Empezamos el algoritmo observando las variables con un matrixplot:

Y un diagrama de correlación:
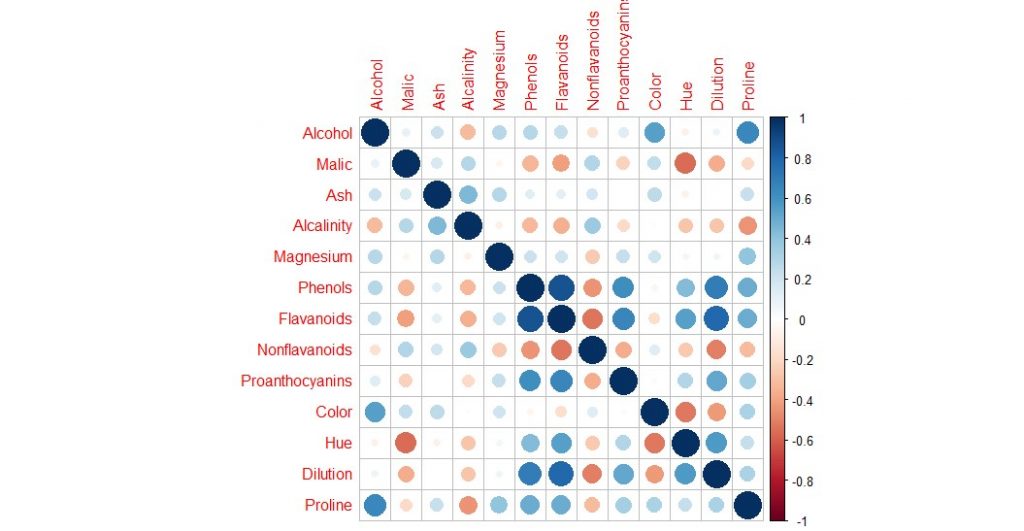
En esta imagen vamos a ver qué características de la composición química están más relacionadas (positivamente en azul y negativamente en rojo)
El siguiente paso es estandarizar los datos para que no haya problemas de unidades.
Es decir, cada variable tiene su unidad (peso, densidad, euros etc…)
Aquí se trata de quitar la media de las variables y dividir por la desviación estándar para crear variables de media 0 y dispersión 1.
Mira más sobre estandarización aquí.
De esta forma no tenemos el problema del conflicto de unidades y el clustering será más efectivo.
El siguiente paso es encontrar el número óptimo de clusters.
Es decir el número de grupos que existen estadísticamente diferentes según los datos que tenemos.
En este caso encontramos 3:

En el gráfico puedes observar que se ha marcado el número óptimo de clusters que es 3.
Vamos a seguir.
El siguiente punto es aplicar un algoritmo de clustering.
En este caso vamos a utilizar el algoritmo de k-means o k medias.
Te explico más en este vídeo:
Aplicando el algoritmo de cluster k-means que acabas de descubrir este es el resultado.
Los dos ejes que ves son los ejes de las dos primeras componentes principales.
Algún día te hablaré de ello 😉

Fíjate aquí que se puedes distinguir tres grupos bastante diferenciados.
El siguiente paso es calcular las medias para cada variable de composición química.
Vamos a verlo:

De estos tres clusters podríamos analizar si hay diferencias significativas entre clusters y encontrar aquellas que definen mejor el grupo de vinos según la composición.
Esta última parte interpretativa nos dará conclusiones interesantes de tus datos.
Podrías con la ayuda de los intervalos de confianza de la media y la descriptiva con boxplots comparar grupos.
Esto es clustering o segmentación y es una herramienta muy interesante para aplicarla siempre que quieres crear segmentos de datos.
Los principales algoritmos de clustering
Ahora te voy a listar los algoritmos más utilizados para la segmentación de datos.
Te he explicado el algoritmo de k-means con el vídeo.
Pero existen otros bastante comunes y útiles.
Para no alargar el artículo te he vinculado los tres algoritmos más utilizados con contenidos de Wikipedia para que puedas entender cómo trabajan estos algoritmos.
Pero antes voy a tratar de darte una pincelada de cada uno:
- Hierarchical clustering: utiliza las distancias entre observaciones para construir un árbol de distancias y a partir de eso cortar en clusters.
- K-means: también utiliza las distancias entre puntos. Y agrupo los clusters según lo cerca que están de los centros de gravedad de los clusters. A priori, tienes que saber cuántos clusters vas a crear para que el algoritmos sepa dónde colocar cada punto.
- Gaussian mixture models: utiliza modelos gaussianos o modelos de distribuciones normales de diferentes formas para que puedas crear grupos en forma de elipses. Para cada punto se le calcula la probabilidad de pertenencia a cada modelo gaussiano.
Hay otros algoritmos, pero en la práctica k-means y Gaussian Mixture models funcionan muy bien.
Te invito a que le eches un vistazo cómo trabajan en Wikipedia.
Los pasos del clustering
Estos son los pasos que puedes seguir cuándo vayas a aplicar segmentación de datos:
PASO 1 – Estandarización
Para calcular buenos clusters es necesario estandarizar los datos.
Es decir, hacer que tus variables cuantitativas tengan media 0 y desviación estándar 1.
Para evitar problemas de unidades.
PASO2 – Dibujar el matrixplot y la correlación entre características
Es importante hacerte una idea de las variables que están más relacionadas entre sí para saber qué variables pueden dominar los clusters.
En el fondo, describir tus variables cuantitativas.
PASO 3 – Calcular el número óptimo de clusters
k-means y Gaussian mixture models nos ofrecen estrategias para calcular el número óptimo de clusters.
Y es fundamental para realizar una buena segmentación.
PASO 4 – Calcular los clusters con diferentes técnicas
Calcula los clusters con diferentes técnicas (k-means, GMM o hierarchical).
Dibuja los clusters que has calculado y mira cuál de las técnicas produce clusters con más sentido real para ti.
Que sean grupos interpretables. Que tengan sentido.
Decide la técnica que mejor se adapte a tu caso
PASO 5 – Compara los clusters que has calculado
El último paso es comparar las características de los grupos que has creado con la técnica seleccionada en el paso 5.
Y ver si encuentras diferencias significativas entre grupos según las características y en qué variables se ven esas diferencias.
Se trata de aportar una interpretación real a los clusters que has encontrado.
Esto te ayudará a interpretar los clusters que has calculado.
…
Y hasta aquí el artículo sobre segmentación.
Creo que es un buen comienzo este artículo en el mundo de la segmentación y te puede ayudar a seguir creciendo en la ciencia de los datos.
¿Te ha sido útil el artículo? Te espero en los comentarios.


Excelente articulo gracias por compartir
Gracias Jose
Muchas gracias por el artículo, pero que hay si nos enfrentamos a variables categóricas?
Muchas gracias
Gracias una vez mas por compartir con nosotros estos conceptos tan interesantes.
Excelente explicación! 👌