

¡Aquí tienes el primer superpost! No pierdas más el el tiempo en buscar en internet. Tienes el resumen de Estadística definitivo. Este post está diseñado para que sigas un camino conceptual que va desde 0 conocimiento a un bueno. Sino entiendes alguna cosa ves para arriba para encontrar el significado. No olvides de ponerlo en favoritos. Lo vas a agradecer. ¡Ya lo verás!
¿Te ha servido el post? Está resumido lo sé, pero ¿se entiende bien?

Muchas Gracias Jordi! Excelente material, muy claro todo…
Para eso está! 😉
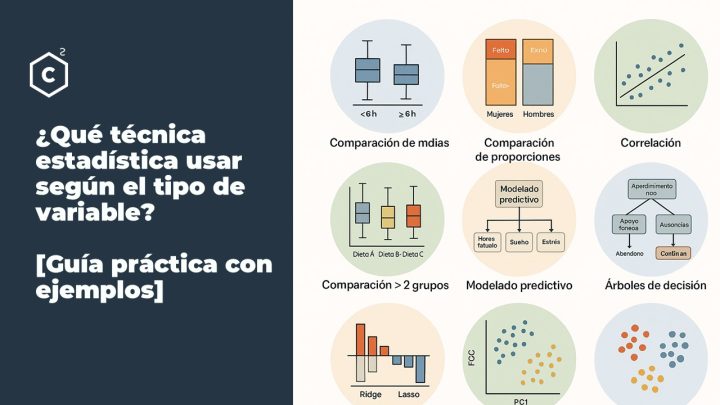
CUAL ES LA MEDIDA MAS ADECUADA PARA CENTRALIZAR LOS DATOS
Hola Gilary!
Las medidas de centralidad pueden ser la media o la mediana.
Si tienes distribuciones en forma de montaña. Es decir un histograma simétrico parecido a la distribución normal utiliza la media.
Si tienes distribuciones diferentes a la distribución en forma de montaña utiliza la mediana.
Si lo que quieres es centralizar los datos. Es decir escalar los datos. Lo mejor es quitar la media y dividir por la desviación estándar. (X-Media)/Desviación Estándar.
De esta manera conseguirás tener la variable numérica centrada en 0 y desviación estándar 1.
Espero que te sirva!
Un abrazo!
gracias jordi muy bueno
De nada Rafael!
Gracias por comentar!
Este material es justo mi idea que en un correo te comente
Creo que esto es lo que hay que enseñar como un razonamiento logico-estadistico
o como logico-investigativo.
Con C2 y ejemplos cocinados poder desarrollar en el estudiante ese ojo que le permita
al futuro investigador dejar que los datos hablen.
Claro concidero que es previo a quererlo hacer investigador
Gracias Roberto!
ültimamente he recibido muchos emails y voy un poco liado. A lo mejor se me ha saltado alguno!
Gracias por tus mensajes!
Una vez mas gracias Jordi, entendí de maravilla todo ahora falta llevarlo a la práctica es verdad que es inconcebible un profecional que no domine aunque sea un poco la estadistica saludos Ernesto R
Gracias Ernesto!
Poco a poco vamos avanzando!
1 placer!
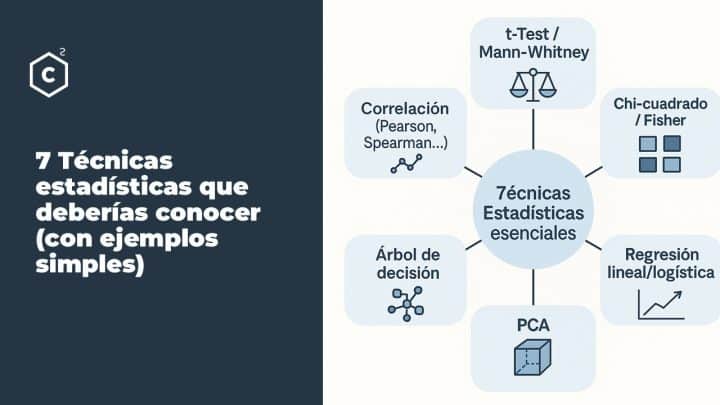
Hola Jordí, los comandos para los para dibujar el boxplot, el qqplot mediante plotly no están en el R que se descarga.
Podrías enviarmelos?.
Alan
Están a bajo del código 🙂
# Dibujamos el boxplot de x
plot_ly(y = muestra[,1], type = «box»,name = » «)%>%
layout(title = «Box-Plot»,yaxis = list(title = «Muestra X»))
# Dibujamos el qqplot de x
gg_qq(x,distribution = «norm»,labels = «x»)
Excelente post Jordi! Estoy comenzando a meterme en el mundo del machine learning y en la mayoría de los tutoriales y kernels utilizan estos conceptos pero sin explicarlos. Este post me ha servido de maravilla para recordar conceptos que hace un tiempo estudié en facultad pero que tenía un poco olvidados, y son fundamentales para meterse en el mundo de la ciencia de datos. Muchas gracias y saludos desde Uruguay!
¡Claro que sí!
Es importante volver a las bases y asentarlas.
Es el primer tema de mi programa formativo de pago Analiza tus Datos y es completamente esencial 🙂
Más info:
https://events.genndi.com/register/818182175026331371/ae98d21b5c
Abrazos!